
2026.3.6
pirika.comで化学
>チャピエモン-3rd Pirika Origin (CPO)
> ハンセン溶解度パラメータ (HSP)
> 化学全般
> 情報化学 >物性化学 >高分子化学 >化学工学 >その他の化学 >昔のもの
>情報化学ツール >MAGICIAN養成講座 >STEAM
>Pirika ツール群
ブログ
業務案内
お問い合わせ
情報化学 > 情報化学ツール > クラッシクなニューラルネットワーク法
[1. 概要]
1997年ごろ山本博志はつくばの研究所で代替フロンの研究を行っていた。その際にフロンの物性を構造から推算し、必要な物性値を満足するフロンの構造を逆設計するという方針を立てた。物性推算法として新しく脚光を浴びていたニューラルネットワーク(NN)法を採用した。簡単に収束し、とても高い相関係数が得られた。しかし予測性能の低さが問題になった。化学系はデータ数が少ない。教師データに実験誤差が含まれる。コンピュータは遅くメモリーやHDは小さい。そのような時に25年前何をしたのかを書き留めておく事は重要だろう。DL法で問題があった場合には思い出してみよう。
[2. 線形回帰法]
当時の推算式の構築には重回帰法[*1]が使われていた。表1のようなデータがあったとしよう。角度(Degree)とそのSinをとったペアがいくつかある。
| Degree | Sin |
| 20 | 0.34201047 |
| 40 | 0.64277184 |
| 60 | 0.86600996 |
| 90 | 1 |
| 110 | 0.93971199 |
これを図示すると図の1になる。
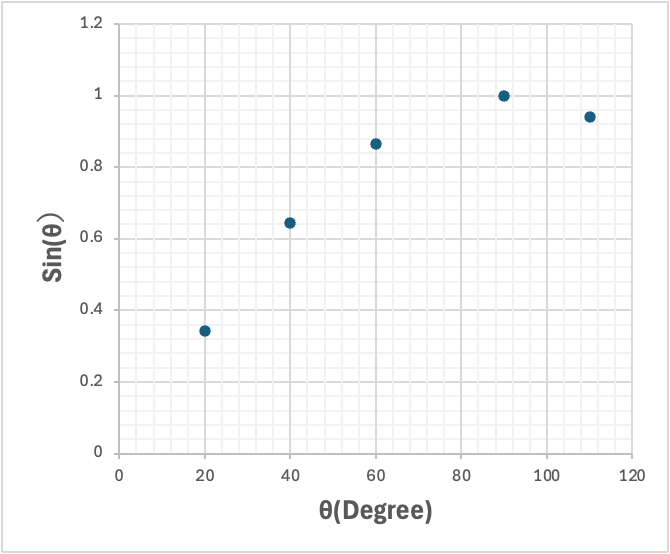
こののようなX−Y関係のデータポイントがあったとする。
図2に示すようにy=ax+bという直線を仮定する。各データ点から直線に垂線を引く。それが誤差になる。5つの誤差の2乗を足し合わせたものを最小にする直線を求める。
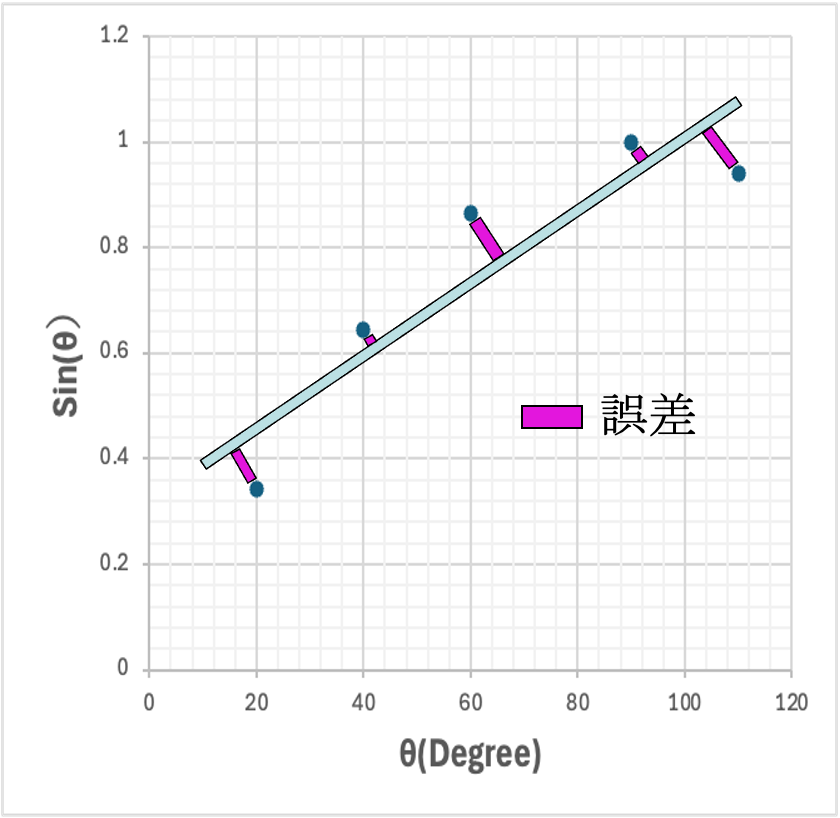
コンピュータのない時代には、方眼紙に描き、定規をあてて決めていた。繰り返し誤差2乗の総和を小さくするように計算するので回帰計算という。最小二乗法とも呼ばれる。
角度とsinの値を拡張した図3に示した。線形の予測式でsinのデータを予測する事は不可能な事は明らかだ。
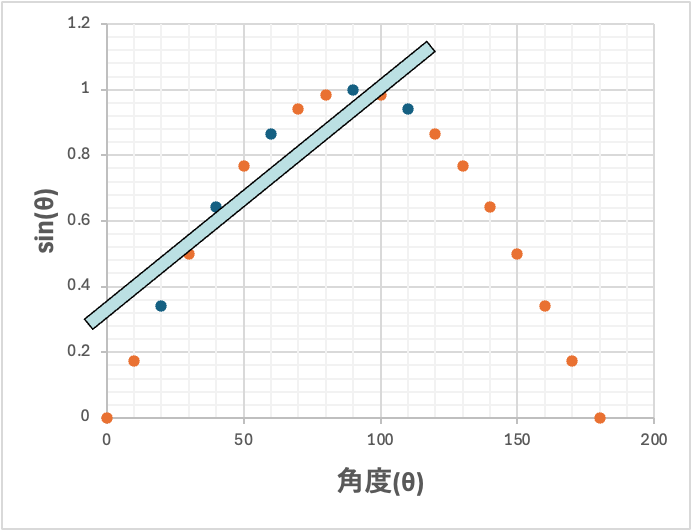
[3. 非線形回帰法]
線形回帰の場合、y=a*x+bという式を仮定した。
非線形回帰の場合には次式を仮定する。
f(y)=A1* / [1+exp(-(B1*X1+B2*1))+
A2* / [1+exp(-(B3*X1+B4*1))+
A3* / [1+exp(-(B5*X1+B6*1))
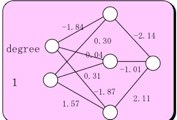
誤差が最小になるA1-A3, B1-B6の組を見つければ良い。
A1= -2.14 B1= -1.84 B2= 0.30
A2= -1.01 B3= 0.04 B4= 0.31
A3= 2.11 B5= -1.87 B6= 1.57
とし、f(y)をプロットすると図4になる。
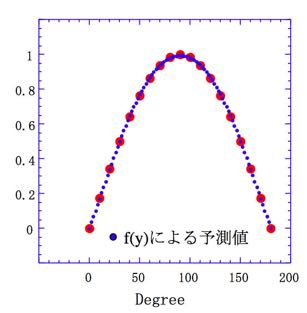
大きな赤丸はf(x)を作るのに使ったデータ・ポイント(学習点と呼ぶ)である。青の小さな丸は求めたA1-A3, B1-B6を使ってf(x)を計算したものになる。良好に非線形性が記述できていることがわかる。
[4. ニューラルネットワーク法]
このf(y)をを模式的に書くと、生体の神経細胞(ニューロン)がつながったような図5になる。そこでニューラルネットワーク法と呼ばれる。左の2つを入力層ニューロン、真ん中の3つを中間層(隠れ層)ニューロン、右の1つを出力層ニューロンと呼ぶ。入力ニューロンの二つ目の入力値(1)はバイアスニューロンと呼ばれる。
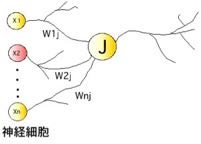
A1-A3, B1-B6を求めるには収束計算を行う。ニューラルネットワークの世界では収束計算と呼ばず、学習という。式中の変数、A1-A3, B1-B6は模式図中でニューロンを同士の結合の強さ(結合荷重行列と呼ぶ)として表わされている。
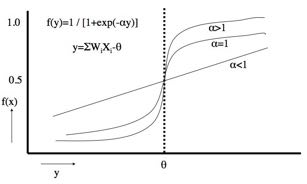
また、f(y)=A1* / [1+exp(-(B1*X1+B2*1))という関数は、シグモイド関数(図7)と呼ばれ、αの値によって、ある閾値θで急に値が変わる関数になる。
これは、生物の刺激ー応答曲線に似ているため、ニューラルネットワーク法と呼ばれている。
[5. 学習アルゴリズム]
一般的な学習アルゴリズムとしては誤差逆伝播法[*3]がある。予測性能が悪いので今ではあまり使われていないと思う。
[6. pirikaの拡張]
シグモイド関数は微分すると、またシグモイド関数になるので、エラーを下げるのにどの方向へ動かしたら良いのかわかりやすい。
しかし、多峰性のデータ[*4]に適用するには適さない。解析的に求めるのでなければシグモイド関数にこだわる必要はない。どのような関数が良いかは研究者がよく考える必要がある。
piriaでは学習のアルゴリズムとしては再構築学習法[*5]を採用している。
[7. Pirika内リンク]
*1 重回帰法
*2 ニューラルネットワーク法の初歩
*3 誤差逆伝播法NN
*4 固体電解質の組成設計は難しい。(多)峰性のデータの解析(前編)
*5 再構築学習法ニューラルネットワーク
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください)
メールの件名は[pirika]で始めてください。