
pirika.comで化学
>チャピエモン-3rd Pirika Origin (CPO)
> ハンセン溶解度パラメータ (HSP)
> 化学全般
> 情報化学 >物性化学 >高分子化学 >化学工学 >その他の化学 >昔のもの
>情報化学ツール >MAGICIAN養成講座 >STEAM
>Pirika ツール群
ブログ
業務案内
お問い合わせ
[0. ストーリー]
深層学習法(DL)はノード同志の結合が非常に複雑になる。そこで非常に多くの学習データを必要とする。ところが化学の分野ではBig Dataは無く、実験誤差を含んだとても汚いデータしか無い。これを教師データにするとDLでは却って性能が出なくなる。得られたネットワークはブラックボックスになる。MIRAI法はノードの結合を研究者が規定する必要があるので使い手のセンスが試される。その分、得られたネットワークは解釈が可能になる。どういう解析ツールを作ればこれが可能になるか? 今ではそれを言語化して生成AIに与えればツールを作ってくれるかもしれない。今無いものを言語化する能力が試される。
[1. 概要]
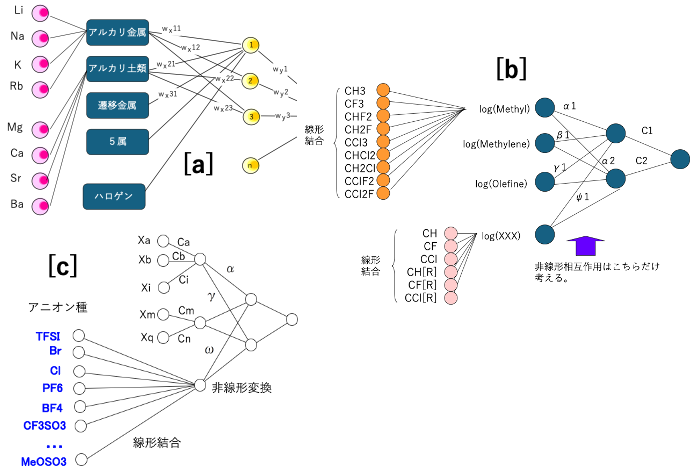
情報化学系非線形解析ソフト、MIRAI(Multiple Index Regression for AI)法はデータ数が少ない、識別子が多い、非線形性があるケースに使う解析ツールだ。pirika.com社の山本CEOによって開発が進められている。熱物性値のようなデータ数が少ない、しかも測定誤差などを含んだ汚いデータを解析するのに適している。MIRAI法ではフィード・フォワード法の一つである遺伝的アルゴリズム法(GA法)[*1]を採用しているので汚いデータに強い。MIRAI法では、動作関数に指数関数やガウス関数を選ぶことができるようになっている。少ないデータで非線形解析をすると、どうしても過学習を起こしてしまう。MIRAI法は一種のニューラルネットワーク法のようなニューロンが結合した形で表される。しかしニューロンの結合を研究者が制限することを求める。似たインプットをグループ化する(図1)。グループ内は線形結合させることによって非線形性を下げる。すると少ないデータ数で収束する。また、線形結合の係数はグループ内の変数間の説明可能性が高くなり逆設計が容易になるという特徴を持つ。
ここでは説明変数のグループ化とMIRAI法の係数の意味を考える。
計算結果=
C0 + Σ[(Ca*Xa+Cb*Xb・・Ci*Xi+1)α
*(Cm*Xm+・・・ +Cq*Xq+1)γ
*(・・・ +Cz*Xz+1)ω ] (1)
[2. ガラスのグループ化と係数の意味]
ガラスの物性推算をニューラル・ネットワーク法[*2]を使って研究することがある。残念ながらBig Dataと呼べるほどのデータは無い。少ないデータでニューラル・ネットワーク法を成立させるには再構築学習法を取り入れるしか無い。MIRAI法を使ったガラスの誘電率推算に関しては既に記載した[*3]。ここではガラス転移温度(Tg)の推算を考える。Appen式によるガラス物性推算法[*4]に示したようにガラスの物性はおおまかには線形回帰法で解析できる。
グループ分けとしては元素の周期律表の属をベース(図1[a])にすることが多い。
[3. 代替フロンのグループと係数の意味]
山本は1995年1月から1999年5月まで地球環境産業技術研究機構(RITE)に出向し、つくばの経済産業省 産業技術総合研究所 物質工学工業技術研究所(当時は通商産業省 工業技術院 物質工学工業技術研究所)にてフロン代替化合物[*5]の開発に携わった。分子構造から物性を全て予測し、候補となる化合物を選び出す。逆設計のソフトウエアーを開発した。代替フロンの物性推算にはニューラル・ネットワーク法[*2]を用いた。プロジェクトで物性値の収集を行ったが、Big Dataは存在し得なかった。そこで、(当時は一部多層化NN法と呼んでいた)MIRAI法を用いてNNのサイズダウンに取り組んだ。グループとしては炭化水素のベースに対して水素をハロゲン原子に置き換えたものをグループのメンバーに入れた(図1[b])。MIRAI法で計算を行うとメチル・グループではCm-Cxの係数が求まる。
(Cm*CH3+Cn*CF3+Co*CHF2+Cp*CH2F+Cq*CCl3・・・ +Cx*CCl2F)γ
[4. イオン液体のグループと係数の意味]
イオン液体はカチオンとアニオンから構成される。カチオンの構成はバラエティーが大きいがアニオンは10種類程度である。イオン液体の密度、粘度、イオン伝導度の物性推算にMIRAI法を用いた。どのアニオンを使ったかはbitで入力する。TFSIを使ったらTFSIの列に1を入れ他アニオンの列は0を入れる。これをMIRAI法を用いて解析すると各アニオンの係数が求まる。
(Cm*TFSI+Cn*Br+Co*Cl+Cp*PF6+Cq*BF4・・・ +Cx*MeOSO3)γ
[5. フッ素ゴム系のパッキンの配合設計]
[X. 図表]
[X. pirikaへのリンク]
*1: 遺伝的アルゴリズム
*2: 再構築学習法ニューラル・ネットワーク
*3: ガラスの誘電率推算法(NN法、MIRAI法)
*4: Appen式によるガラス物性推算法
*5: フロン代替化合物
フッ素ゴム系のパッキンの配合設計
今回の解析では、パワー関数の掛け算でベータの値を再現する式を構築し、学習に含めなかった処方の結果を推算しています。
4種類の推算式を構築してしまえば、後はコンピュータ上で片っ端に評価がオール5になる処方を探させれば良いのです。
このMIRAIの機能は、GROVEに統合する予定です。
塗料、インク、化粧品の特許への応用例をこちらにまとめました。
Copyright pirika.com since 1999-
Mail: yamahiroXpirika.com (Xを@に置き換えてください) メールの件名は[pirika]で始めてください。
特に最近のニューラルネットワーク法はディープ・ラーニングを採用しているため、どうしてもビッグデータを必要としてしまう。画像解析や言語解析と比べ化学の物性値にはビッグデータは存在しない。最近の生成系AIの発展により、ちまちま物性値を測定するような研究は今後は激減していくと思われる。一生懸命測定してもその成果はAIに皆横取りされてしまう。通常の誤差逆伝播法を用いたニューラルネットワーク法は教師データに誤差が含まれる場合にはとても悪い結果しか与えない。
また、ニューラルネットワーク法で主に使われているシグモイド関数は一般的な非線形性を表すには良いのだが、ある所に最適値があるようなスパイクを表現するには適さない関数になる。自分の好きなアニメのDr. Stone
獅子王司の妹の名前もミライちゃんだ。
普通のMI(Materials Informatics)を仕事に活かせない業界は非常に多いようです。
ここでは、特許に記載されている一例を紹介します。
2列目は官能評価(とても良いと感じる=5、とても悪いと感じる=1)結果です。
その後の列は、配合成分です。それぞれの成分は市販品として販売されており、正確な内容はわかりません。
カーボンブラックのようなものを想像してください。CB(A-1)はW社から、A-2はX社から、A-3はY社から購入しています、などです。
分かっているのは、それぞれの成分をどれだけ使って配合したか、官能評価値がいくつ得られたかだけです。
さらに、官能評価には複数の種類があります。
私たちがやりたいのは、MIを使って、複数の官能評価値の予測値が得られ、すべての評価値が5点になるような処方を設計することです。
しかし、この場合、RDKitの識別子も分子軌道計算の結果も使えません。
また、官能評価には何人もの人のデータを集めるため、データを増やすことも容易ではありません。
この問題に対して、MIの研究者はどうすればいいのでしょうか?
腕に自信のある人は、次のデータで予測式を作り、予測処方の値を予測してみてください。
テキストエリアにあるデータをコピーしてエクセルなどにペーストしておいてください。
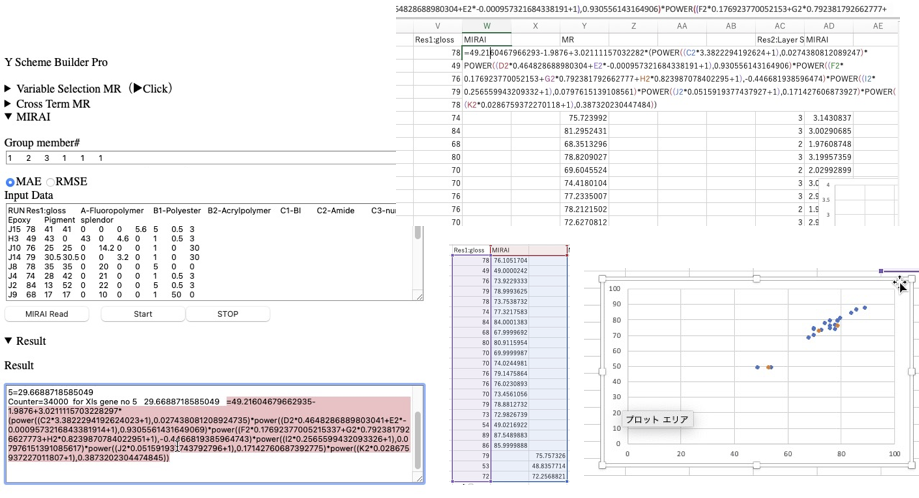
Pirikaには新しい分析ツール、MIRAI(Multiple Index Regression for AI)があります。
今回、このツールをWebアプリ化しました。
エクセルのテーブルをソフトにペーストして、グループ分けもペーストして、ソフトを走らせます。
計算にはとても長い時間がかかります。手順を学ぶ為、計算結果を模擬的に返すWebアプリのCalcボタンを押し、計算結果の=以降をコピーしてエクセルに戻します。
MIRAI
Input Data
Group
Result
計算結果を適当な列の2行目にペーストしてグラフを描いてみましょう。次のようなグラフが得られれば成功です。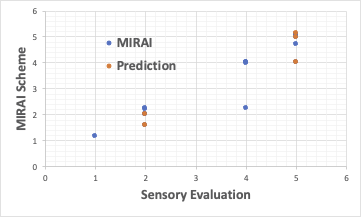
通常の重回帰解析では、次のようになります。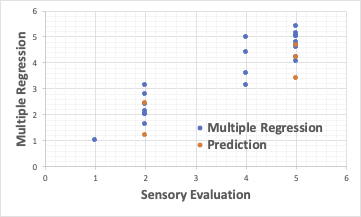
重回帰法の欠点として、説明変数間に相互作用があるもの、非線形なものには使えないことが挙げられます。
それに対して、MIRAIはフィードフォワード型のニューラル・ネットワーク法で、データ数がこのように少なくても、予測性能を維持できるように設計されています。